

















DOMINUS
«EDEM CORP» - Старейший сервис Даркнета
Старший модератор
Модератор
Проверенный продавец
Legend user
DOMINUS
«EDEM CORP» - Старейший сервис Даркнета
Старший модератор
Модератор
Проверенный продавец
Legend user





- Статус
- Online
- Регистрация
- 20 Дек 2015
- Сообщения
- 4,622
- Реакции
- 418
- Депозит
- 3.000р
- Покупки через Гарант
- 0
- Продажи через Гарант
- 12
Анализ фотографий и социальных связей может стать огромным подспорьем при социальной инженерии.
Анализ фотографий и социальных связей может стать огромным подспорьем при социальной инженерии. Если мы знаем, кем является персона и круг знакомых этой персоны, то вполне можем выявить связи внутри компании, что впоследствии позволит реализовать изощренные целевые атаки с использованием социальной инженерии.
Термин OSINTили по другому разведка на основе открытых источников охватывает такие сферы, как анализ, оценку и применение публично доступной информации. Приведу цитату ЦРУ: «Чтобы получить нечто ценное, не обязательно пытаться достать исключительно конфиденциальную информацию. Понимание окружающей реальности приходит через чтение блогов и специальных журналов, просмотр телевизора и изучение других общедоступных источников».
Помимо текста общедоступная информация хранится в интернете в виде фотографий, которые, в основном, фильтруются и обрабатываются людьми вручную при помощи графического редактора с целью последующего анализа полученных результатов. Однако с появлением программного обеспечения, заточенного под распознавание лиц, многие операции стало возможным автоматизировать.
По поводу технологии распознавания лиц уже появилось много статей и дискуссий, например, касательно биометрии или того, как эта технология влияет на информационные массивы и частную жизнь. Несмотря на то, что распознавание лиц в основном используется на таких платформах какFacebook или правоохранительными органами по всему миру, любой желающий может воспользоваться схожими бесплатными приложениями с открытым исходным для решения своих собственных задач.
В этой статье мы рассмотрим, как использовать библиотеку Face Recognitionна базеPython для поиска и анализа изображений. Кроме того, мы рассмотрим пакетную обработку фотографий и методы получения статистики с целью того, чтобы впоследствии сделать выводы об отдельной персоне или целом вебсайте.
Шаг 1: Установка зависимостей
Библиотека Face Recognition, которую мы будем использовать, доступна напрямую в менеджере пакетовPip вLinux иmacOS. Несмотря на то, что этот пакет вWindowsофициально не поддерживается, доступно руководство по установкеи сконфигурированный образ виртуальной машины.
Перед началом установки проверьте, присутствуют ли последние обновления в вашей операционной системе. В дистрибутивах на базеDebian(например,Ubuntu иKali) обновление и установка нового программного обеспечения делается при помощи следующей команды:
sudo apt-get update && apt-get upgrade
В некоторых дистрибутивахPip доступен по умолчанию. В противном случае последнюю версию этого менеджера можно установить при помощи следующей команды:
sudo apt-get install python-pip
Рисунок 1: Установка менеджера пакетовPip
Далее устанавливаем библиотекуFace Recognition при помощи следующей команды:
sudo pip install face_recognition
Рисунок 2: Установка библиотекиFace Recognition
Теперь библиотека готова к использованию.
Шаг 2: Организация информации для анализа
Если библиотека для распознавания лиц реализована наPython, значит, мы можем относительно просто внедрить эту библиотеку в другие приложения. То есть, по сути, мы можем расширить функционал веб-камер, поисковых ботов и других приложений, где доступны лица в цифровом формате. Хотя с другой стороны нам может потребоваться написание дополнительного кода. Чтобы упростить задачу мы будем использовать утилиту, управляемую из командной строки, в связке с другими системными инструментами для выполнения схожих функций, но без необходимости в написании новых скриптов.
Идущая вместе с библиотекой утилита позволяет работать с двумя наборами картинок. В одной папке будут находиться фотографии для анализа, в другой – коллекция изображений, которые пользователь хочет сравнить с первым набором.
Чтобы создать массив картинок для фильтрации на предмет присутствия определенных лиц, мы можем рекурсивно загрузить весь сайт, показанный ниже, при помощиWget. В реальной жизни пентестер или исследователь в качестве источника изображений может использовать сайты компаний, галереи, социальные сети и другие источники.
Рисунок 3: Пример сайта для загрузки изображений
Сwget можно работать из командной строки и загружать как отдельную страницу или картинку, так и целые веб-сайты. Команда, показанная ниже, позволяет пройтись по каждой ссылке внутри заданного домена и загрузить все доступное содержимое. Чтобы принудительно прекратить загрузку, необходимо нажать комбинацию клавишCtrl+C. В противном случае процесс весь процесс завершится после загрузки всего содержимого.
wget -p -r -E -e robots=off --convert-links -U mozilla --level 1whitehouse.gov

Рисунок 4: Загрузка содержимого сайтаwitheghouse.gov
·Флаг–p предписывает, что дополнительный контент в виде картинок, стилей и скриптов также будет загружаться.
·Флаг–Eпредписывает, что каждый загружаемый файл будет сохраняться вместе с полным расширением, чтобы впоследствии мы легко смогли отфильтровать картинки.
·Флаг-rпредписывает, что загрузка должна быть рекурсивной. Соответственно, информация по другим ссылкам и в других директориях также будет загружаться.
·Флаг--level1задает уровень рекурсии. То есть в данном случае информация будет загружена только по ссылкам со стартовой страницы. Чтобы увеличить глубину рекурсии, необходимо либо увеличить значение этого ключа, либо убрать ключ совсем (тогда глубина рекурсии будет бесконечной).
·Флагdomainпредписывает, что загрузка должна осуществляться исключительно в рамках заданного домена.
·Помните, что рекурсивные запросы могут быть заблокированы или стать причиной проблем на некоторых серверах. То есть желательно либо ограничить глубину рекурсии или воспользоваться флагом-w, чтобы между запросами была задержка.
·Флаг-e robots=offпозволяет избежать игнорирования или блокировки запроса как от нежелательного поискового бота.
·Ту же задачу решает флаг-U mozilla, который определяет параметрuseragent, чтобы наши запросы воспринимались как от легитимного браузера.
·Флаг--convert-links конвертирует ссылки, чтобы впоследствии мы смогли использовать скачанные страницы без каких-либо проблем. Этот флаг напрямую не связан с фильтрацией изображений, но упрощает задачу поиска местонахождения картинок.
Как только мы настроили сборщик картинок в течение определенного времени, то можем создать дубликаты файлов в новой директории для упрощения последующей работы. Вначале создадим новую папку при помощи следующей команды:
mkdir unknown_faces
Затем копируем все изображения, скачанные при помощиwget, в новую директорию при помощи двух команд, показанных ниже. Вначале копируем всеJPG-файлы, потом – всеPNG-файлы. Строкаurlfolder должна быть заменена на папку, кудаwget сохранил загруженное содержимое. Обычно название этой директории связано с именем домена.
cp urlfolder**/*.jpg unknown_faces/
cp urlfolder**/*.jpg unknown_faces/
Командаcpкопирует все файлы, удовлетворяющие фильтру и находящиеся внутри указанной директории (в нашем случае -whitehouse.gov). Двойная звездочка, используемая в названии папки, определяет рекурсию. Одинарная звездочка предписывает, что должны быть скопированы все файлы с расширением JPG или PNG. Последний параметр предписывает, что все файлы должны быть скопированы в папку unknown_faces.

Рисунок 5: Копирование загруженных картинок в новую директорию
После того как картинки перемещены в новую директорию, мы можем просмотреть содержимое этой папки при помощи командыls.
ls unknown_faces/
Рисунок 6: Содержимое директории unknown_faces
Мы также можем при помощи оператора | перенаправить этот список на вход другой команды, чтобы посчитать количество загруженных фотографий. Эта фишка может пригодиться для выяснения, насколько часто определенное лицо встречается среди набора изображений. В команде, показанной ниже, результат предыдущей команды перенаправляется на вход командыwc с флагом –l с целью подсчета количества строк.
ls unknown_faces/ | wc -l

Рисунок 7: Подсчет строк, выводимых командойls
В результате выяснилось, что мы загрузили 178 картинок. Как только изображения готовы к использованию, можно приступать к распознанию лиц.
Шаг 3: Подготовка списка для идентификации
Перед подготовкой списка лиц или других признаков, которые мы хотим найти в массиве загруженных изображений, нужно создать новую директорию вне папки, созданнойwget. Переместимся на уровень выше при помощи команды cd ../, создадим папку known_faces, используя командуmkdir known_faces, и перейдем в новую директорию.

Рисунок 8: Создание новой директории
Затем в новую директорию нужно скопировать изображения, которые мы хотим найти на загруженных фотографиях. В идеале нужно использовать фотографии лиц сродни тем, которые часто используются на веб-страницах с контактами. На каждой фотографии, используемой для сравнения, должно быть только одно лицо. Для удобства можно переименовать файл так, чтобы имя соответствовало персоне, изображенной на фото, поскольку в случае совпадения, будет возвращаться имя файла.
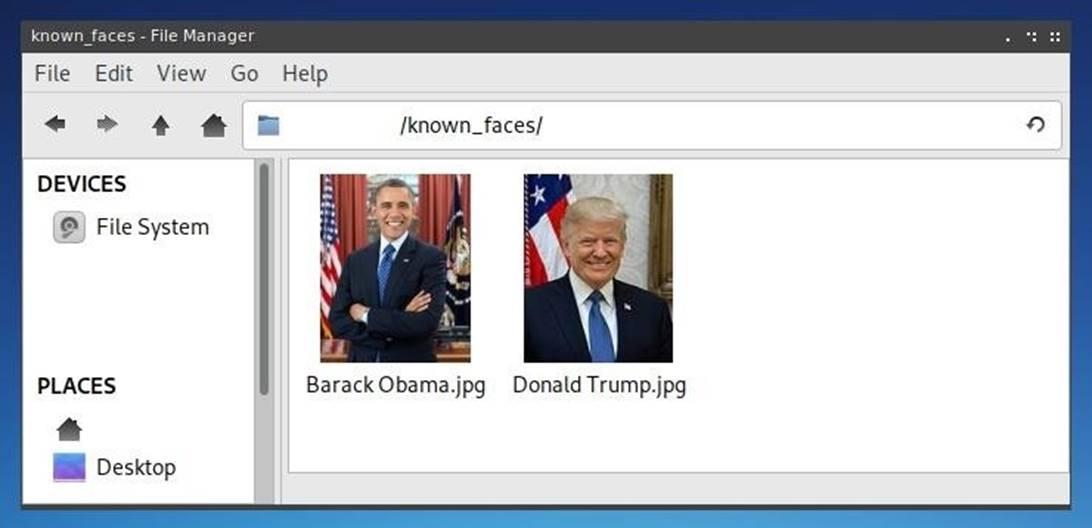
Рисунок 9: Фотографии, используемые для сравнения
Как только фотографии в обеих директориях подготовлены, приступаем к использованию утилитыface_recognition.
Шаг 4: Распознавание лиц
Утилита, позволяющая работать из командной строки, которая идет вместе с библиотекойFace Recognition, относительно проста в использовании и требует всего два параметра. В первом параметре нужно указать директорию с изображениями, которые мы хотим найти (known_faces), во втором параметре нужно указать директорию с изображениями, среди которых будет осуществляться поиск (unknown_faces). В итоге команда выглядит так:
face_recognition known_faces/ unknown_faces/
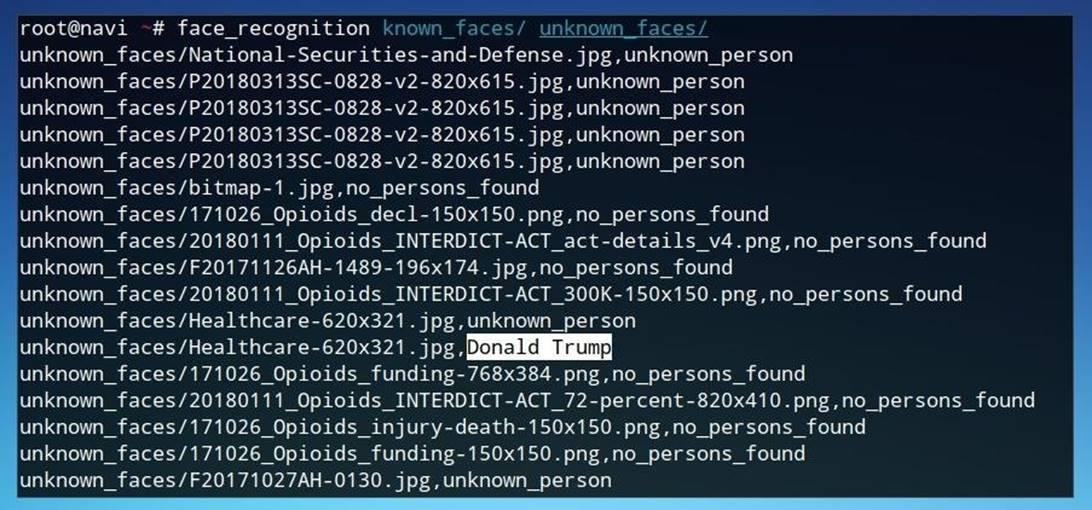
Рисунок 10: Поиск известных лиц на фотографиях
По каждой фотографии будет выведен один из следующих результатов: «имя одного из файлов» (значит, найдено известное лицо), «неизвестное лицо» или «не найдено ни одного лица». Чтобы впоследствии автоматически обработать полученную информацию, можно перенаправить результаты выполнения в текстовый файл при помощи оператора >.
face_recognition known_faces/ unknown_faces/ > results.txt
В дальнейшем мы будем использовать этот текстовый файл для анализа результатов поиска.
Шаг 5: Анализ результатов поиска
Один из возможных вариантов анализа результатов работы утилитыface_recognition – получение списка файлов, в которых найдено одно из лиц. Например, при помощи утилитыgrep, на вход которой подается файлresults.txt, получим перечень всех файлов, где нашлось лицо из файла с именемDonald Trump.
grep "Donald Trump" results.txt
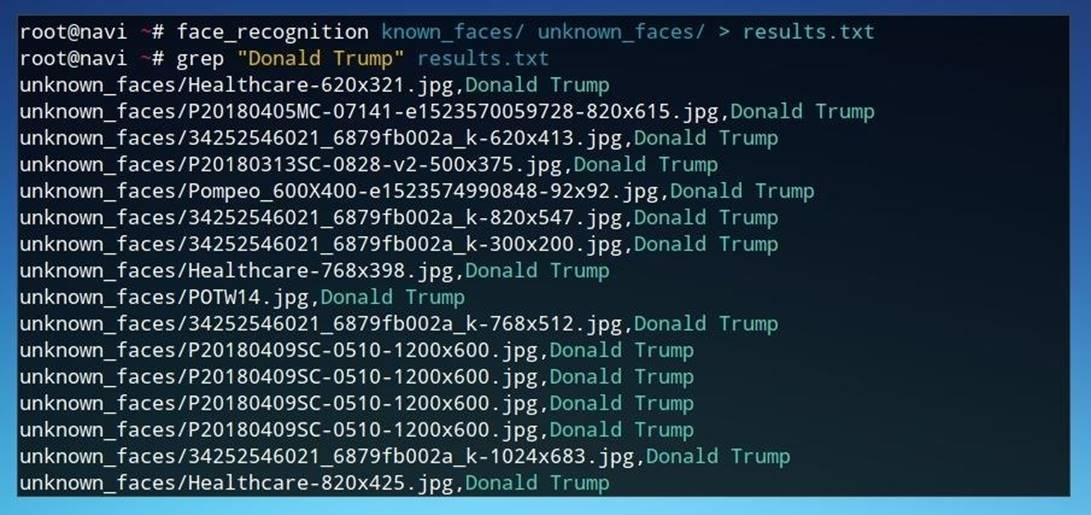
Рисунок 11: Список совпадений с файломDonald Trump
Мы также можем использовать комбинацию других системных утилит для вычисления частотности каждого из результатов.
cat results.txt | sed 's/.*,//' | sort | uniq –c
Вначале командаcat results.txtвыводит содержимое файлаresults.txtв стандартный поток ввода. Затем полученные результаты отправляются в потоковый редакторsed, который удаляет все до и включая запатую. Далее список группируется при помощи утилитыsort. В самом конце производится подсчет количества вхождений при помощи командыuniq –c.
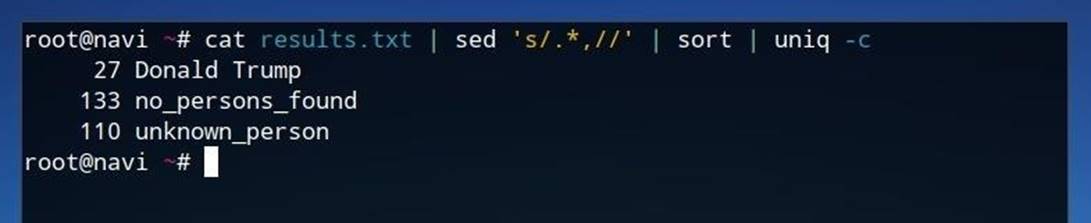
Рисунок 12: Подсчет частотности результатов поиска
В результате выполнения команды выше мы получаем список уникальных совпадений и частотность каждого совпадения.
Если мы хотим получить список определенных изображений, найденных утилитойface_recognition, то можем использовать схожую технику. Например, при помощи команды ниже создадим новый текстовый файл с перечнем результатов поиска, удовлетворяющих определенному критерию.
grep "Donald Trump" results.txt | sed 's/,.*$//' > identified.txt
Вначале при помощиgrepв файлеresults.txtищем все результаты, где есть строкаDonald Trump. Полученные результаты отправляются вsed, где в каждой строке все содержимое после запятой, включая саму запятую, удаляется. Итоговые результаты сохраняются в файлеidentified.txt (делаем перенаправление при помощи оператора >).
Если мы запустим командуhead identified.txt, то увидим только список файлов, который, например, можно использовать в качестве входного параметра еще одного скрипта для копирования всех этих файлов в новую папку.
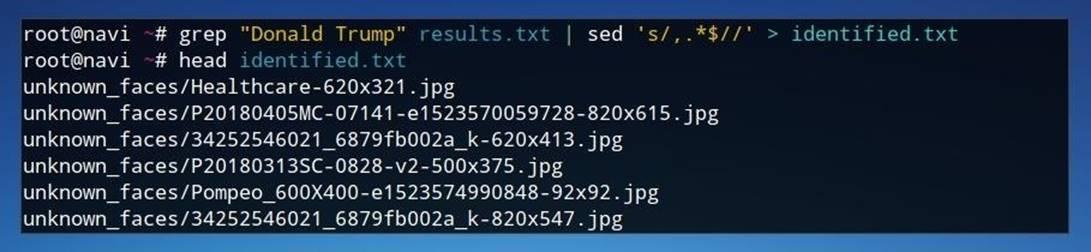
Рисунок 13: Пример команды для фильтрации списка файлов
Новый скрипт можно создать в редактореNanoпри помощи командыnano identified.sh.
#!/bin/bash
mkdir identified
while read line; do
filename=$(echo $line | sed 's/.*\///')
cp $line identified/$filename
done < identified.txt
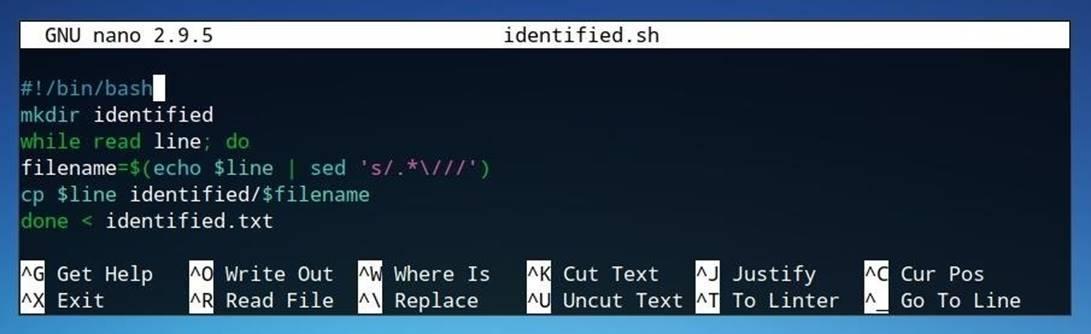
Рисунок 14: Создание нового скрипта
·В первой строке, #!/bin/bash, декларируется, что скрипт предназначен для оболочкиBash.
·Во второй строке создается новая директория identified, куда будут перемещены все найденные файлы.
·Третья и последняя строка образуют цикл чтения строк из файлаidentified.txt. Каждая строка файла модифицируется внутри конструкцииwhile.
·В первой строке цикла (четвертая строка кода) создается переменнаяfilename. Этой переменной присваивается имя файла, полученное после обработки строки потоковым редакторомsed. В каждой строке удаляется все содержимое до слэша.
·Эта переменная используется в последней строке цикла в команде, которая копирует файл в директориюidentified и назначает скопированному файлу имя из переменнойfilename.
После того как редактирование закончено, сохраняем скрипт, нажав комбинацию клавишCtrl+O. Для выходи из редактора нажимаемCtrl+X. После того как скрипт сохранен в файлеidentified.sh, добавляем права на выполнение при помощи командыchmod +x.
Далее запускаем скрипт при помощи простой команды./identified.sh.

Рисунок 15: Добавление прав на выполнение и запуск скрипта
После завершения выполнения скрипта, в директорииidentifiedбудут находиться все изображения, которые удовлетворяют вашему фильтру. Как вы могли убедиться, весь процесс автоматизирован и серьезно экономит время по сравнению с обработкой списка фотографий вручную.
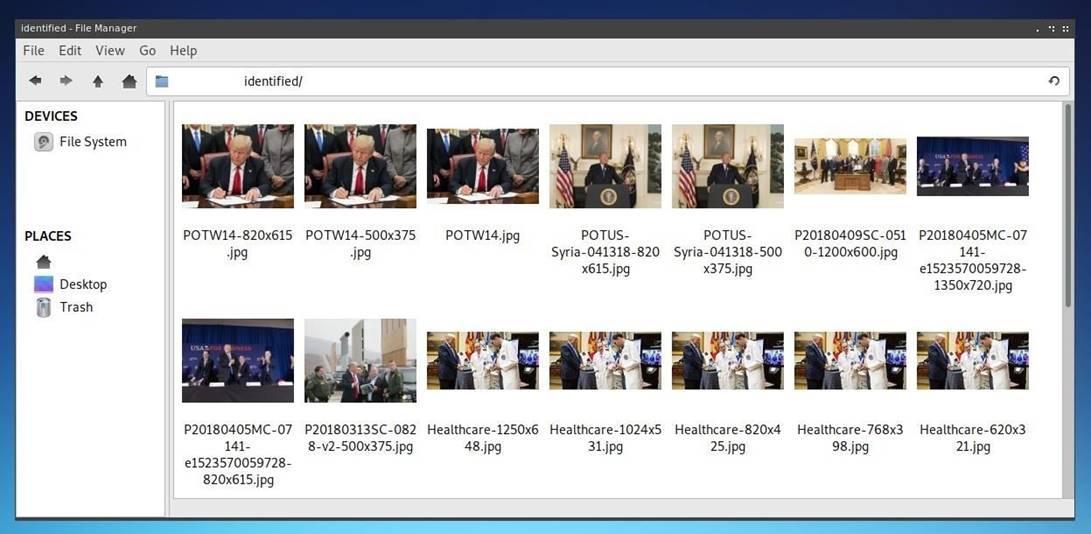
Рисунок 16: Список найденных фотографий
Как защититься от техник, связанных с распознаванием лица
К сожалению, надежно защититься от распознавания вашего лица на фотографиях можно лишь одним способом. А конкретно – перестать выкладывать свои фотографии в сеть и как можно реже появляться в публичных местах. Кроме того, можно выставлять более строгие настройки в ваших аккаунтах, не использовать социальные сети или скрывать свое лицо при появлении в публичных местах. В основном эти методы доставляют много неудобств.
В целом, опасность, связанная с распознаванием лиц, больше относится к данным, привязанным к конкретному профилю или аккаунту, а не сама фотография. Помните, что если вы выложили свои фотографии или поделились другой информацией в сети, то уже нельзя быть уверенными в полной защищенности.
Автор:TAKHION


